< dash> herrFoo: the difference between a unicode string and an encoded byte string is exactly the same kind of difference as between the list [1, 2, 3] and the string "[1, 2, 3]"
El nivel de la ensalada que se arma en la cabeza a la hora de entender Unicode hace que el tema deba explicarse una y otra vez, que se deban escribir ad infinitum posts, mails, dar chiquicientas charlas en conferencia y tal. En un intento de darle fin (si, jua!) a semejante derroche de recursos es que escribimos esta página.
Bienvenido a La Última Página Acerca De Unicode Y Cómo Se Usa (O «cómo aprendí a dejar de preocuparme y odiar los encodings»).
Intro
Resulta que las tontas de las computadoras sólo saben pensar en función de números. Esto es todo un problema al momento de almacenar y manipular otras cosas, como los textos. Afortunadamente es posible hacer una relación entre números y cosas.
Entonces, desde los tiempos inmemoriables las computadoras han representado los símbolos que nosotros usamos en la escritura con múmeros. Inicialmente esta asociación era evidente, pero últimamente (digamos, en los últimos 50+ años, o sea, casi toda la historia de la computación) las computadoras nos han estado engañando, pues al presentarnos resultados impresos no nos dan los números que usan internamente. En vez, con la ayuda de pantallas, impresoras y otras cosillas por ahí (terminales Braille, por ejemplo), nos han estado devolviendo los símbolos a los que estamos acostumbrados: letras, dígitos, putuación y otros. Nosotros, claro, chochos. Este mapeo entre símbolos y números se llama Encoding, pues codifica los símbolos en números (y viceversa; si me apuran, les cuento que no es más que una función biyectiva).
Todo estaría de maravillas sino fuera que Encodings hay millones. Estos mapeos fueron establecidos casi independientemente en muchas empresas y países del mundo, cada uno prácticamente con el suyo. La mayoría de los Encodings usan sólo un byte (8 bits) para almacenar el número, así que sólo cabía la posibilidad de 256 símbolos, lo cual claramente no alcanza para todos los símbolos del mundo. Piensen por ejemplo en los idiomas que no usan ni siquiera como base al alfabeto latín. Así es que terminamos con cientos de Encodings llamados 'latin1', 'utf-8', 'cp-1250' y cosas más esotéricas.
Para resolver este problema es que se inventó Unicode (cualquier semejanza con http://xkcd.com/927/ es un error de concepto; ahora explico porqué). Unicode no es un encoding, aunque se asemeja mucho. Unicode es una serie de tablas de símbolos, nada más. Estos símbolos son no sólo aquellos que encontramos en todos los encodings habidos y por haber (incluyendo la mayoría de los alfabetos usados en el mundo, incluyendo el ya mencionado Braille, y hasta ficticios, como el klingon [sí, klingon, no pregunten]), sino muchos, muchos, muchos más. Demasiados, quizás. Para muestra vale un botón: http://www.fileformat.info/info/unicode/char/1f4a9/index.htm
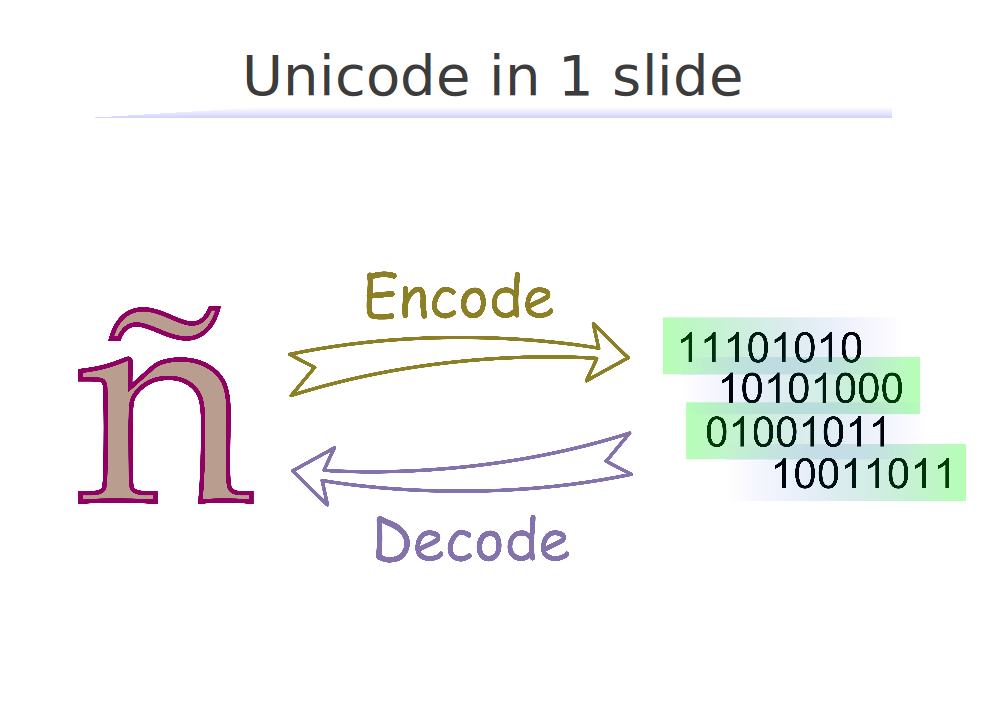
La ventaja de Unicode es que al contener todo, es posible que, dado un Encoding, se pueden encontrar los símbolos que abarca y hacer una traducción Unicode <-> Encoding. Al paso hacia la derecha se le llama Encodeado y la inversa Decodeado. Ver Unicode en una filmina. Notar que como Unicode es más grande (o igual?) que cualquier Encoding, hay símbolos en Unicode que no están en un Encoding dado. El Encodeado de un carácter no presente en el Encoding resulta en el fatídico y über-odiado mensaje:
{kind=link}
Unicode, Encodings y Python
¿Qué tiene tooooodo esto que ver con Python? Bueno, los no muy frescos de zabiola ya se habrán dado cuenta que al fin y al cabo Python corre sobre computadoras y Python maneja cadenas de caracteres (strings). Para dicho propósito Python tiene dos tipos distintos. Inicialmente, en Python2 usa el tipo unicode para representar bichos Unicode y str para representar bichos Encodeados. Esto suele traer millones de dolores de cabeza, pues el tipo str es mayormente (mal) usado en tutoriales para almacenar cadenas de caracteres, cuando se debería usar Unicode. ya explico porqué.
Para complicar las cosas[2], Python3, en cambio, tiene otros dos tipos para ello: str se usa para el almacenamiento de cadenas de caracteres Unicode y bytes para bichos Encodeados. De aquí en más seguiré con la nomenclatura de Python2; si están usando Python3, agreguen a su ensalada el hecho de que cada vez que diga unicode ustedes deben pensar en str, y cuando diga str, ustedes piensen en bytes. Cuando Python3 sea más utilizado, y si aún estoy vivo y con uso de mis facultades, volveré a esta página y les juro que pongo todo en nomenclatura Python3.
Entonces, tamos listoso0 con la nomenclatura: unicode para bichos Unicode y str para bichos Encodeados. La forma de crear un bicho Unicode es muy simple[1]:
El source también existe, y está encodeado
¿Vieron ese [1] que puse más arriba? Bueno, resulta que hay una mentira casi tan grande como una casa en todo esto. Más que una mentira, una vuelta más de rosca. ¿Vieron que dije que cuando uno deja el mundo Python/Unicode uno pasa al mundo Encodeado? Bueno, les cuento, y agárrensé: Los archivos que contienen el código fuente de su programa Python también están Encodeados. Esto trae como consecuencia...
Ver también: